

Most customers have already interacted with conversational AI via a text box or a voice assistant, but what happens when these modes of interaction unite? Multimodal conversational AI takes a single channel silo and breaks it apart, letting people talk using text, images, video, voice, and even gestures. These interactions are all housed in one single conversation.
In this guide, we’ll discuss how multimodal conversational AI works, what it delivers for your business, and how to choose the right platform.
What is Multimodal Conversational AI?
Multimodal conversational AI refers to systems that can receive, interpret, and respond to different types of input. Your customers will be able to type text and send over voice, image, or video data at the same time. Multimodal conversational AI then parses together what they need through what they sent in.
“Multimodal” is the key facet. Multiple modes of communication are employed because humans naturally use a mix of mediums to communicate. In-person customers may point to a picture on a menu when ordering at a restaurant while saying what they want. Multimodal AI is built to take on that level of mixed communication without restraining users to one single channel.
A text-only interface will work for straightforward inquiries. It breaks down when customers want to show you something because the context of the request partly lives in the visuals and in their speaking. Multimodal conversational AI bridges these fragments to best handle the total issue.
Single-Modal vs. Multimodal Systems
Single-modal systems can only handle one type of input. Think of your standard chatbot that just reads and sends back text. A voice assistant can really only process speech. While each works within their lane, it becomes apparent they’re limited.
Limitations show up in pretty predictable ways your customer might find frustrating:
- A text chatbot will not interpret a photo of a damaged product a customer is trying to return
- A voice assistant cannot process documents someone is asking about
- A text system cannot read into the tone of voice or stress of facial expressions
Single-modal systems need the user to adapt to the technology. Multimodal systems cut through those limits offering customers the chance to input what they feel communicates their needs best. This way tech adapts to your customer and not vice-versa.
Core Modalities Explained
Each modality adds another layer that the system can comprehend, below we’ve listed the core ones customers expect:
- Text: This remains the baseline for most conversational AI. These comprise of the documents, form inputs, typed queries and written messages your customers want to send over
- Voice: Spoken language is converted to text for processing but also analyzed for tone, pace, and any strong emotional signals
- Vision/Images: Your customers can send over product images, still photographs, or even screenshots for the system to analyze to gather context, details or content
- Video: Visual information that adds motion and temporal context to the situation. Imagine your customers sending footage of a malfunctioning device to illustrate further than written text could
- Gestures: Physical movement or touch input, this works best in kiosk environments or for accessibility purposes and applications
Conversations naturally have modalities mixing and intermingling so each side of the conversation can get the point across. If a customer uploads a photo of a broken appliance they bought and notes it “makes a grinding noise,” the vendor can assist faster. A multimodal system will be able to fuse image and audio context to give a better response.
How Multimodal Conversational AI Architecture Works
The methodology behind multimodal AI follows a three step structure. It starts with specialized encoders to process each input type, then a fusion layer to combine them, and finally an output module to generate responses. Understanding each layer clarifies why some platforms handle multimodal inputs stronger.
Input Encoders for Each Modality
Before different types of information can be combined, each one needs to be converted into a format the system can work with mathematically. That is where input encoders step in. Each modality has its own specialized encoder because the raw form of each input type differs.
Audio comes through waveform, images become grids of pixel values and text is registered as a sequence of tokens. These cannot be compared or combined directly without first being transformed into a common representational format.
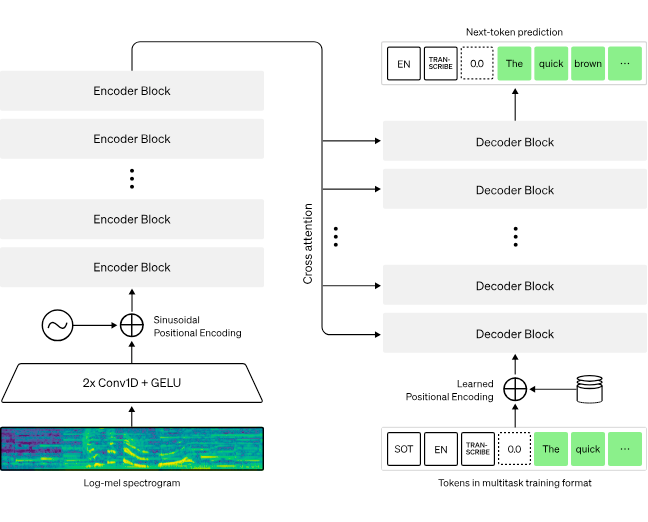
For example, OpenAI's Whisper model handles audio encoding by converting spoken language into text and extracting acoustic features carrying significant emotional and contextual information. For image processing, OpenAI employs a CLIP model to map visual content into the same kind of space as text. This allows its system to understand the relationship between an image and the description of it. Each encoder is a translator, converting specific modalities into a shared language for the system at large.
Fusion Module and Cross-Attention Mechanisms
Once each modality has been encoded, the fusion module is responsible for combining them into a unified understanding of what the user is communicating.
Transformer models handle the combination via a mechanism called cross-attention to parse which parts of one modality are relevant to the parts of another. When someone sends an image and asks "what is wrong with this," the cross-attention mechanism aligns the visual features of the image with the semantic meaning of the question. This is key to producing a grounded or specific response rather than a generic one that misses the point.
The quality of the fusion layer is often what separates genuinely integrated multimodal systems from platforms that have simply bolted separate tools together. A poorly integrated system treats each modality independently and merges the outputs at the end. A well-built fusion layer processes the relationships between modalities in real time, which produces significantly better understanding of complex inputs.
Output Module and Response Generation
The output module takes the fused understanding and generates a response. Depending on the system and the context, that response might be text, synthesized speech, an annotated image, or a combination.
Generating a response that draws on multiple input streams simultaneously requires substantial computational work compared to a standard text response, and latency matters in conversational interfaces.
Users know when a system takes too long to respond, especially in voice interactions where a pause feels robotic. Well-optimized systems can pipeline the processing stages so encoding, fusion, and generation overlap rather than running strictly sequentially.
Key Benefits for Enterprises
Multimodal conversational AI’s business case is staked on reduced user friction, higher accuracy, better contextual awareness, and other facets we cover below.
Reduced User Friction Via Modality Switching
Forcing every user through the same input channel is a design constraint, not a feature. Some users are faster with voice. Some queries are inherently visual. Some situations, like driving or cooking, make typing difficult or impossible.
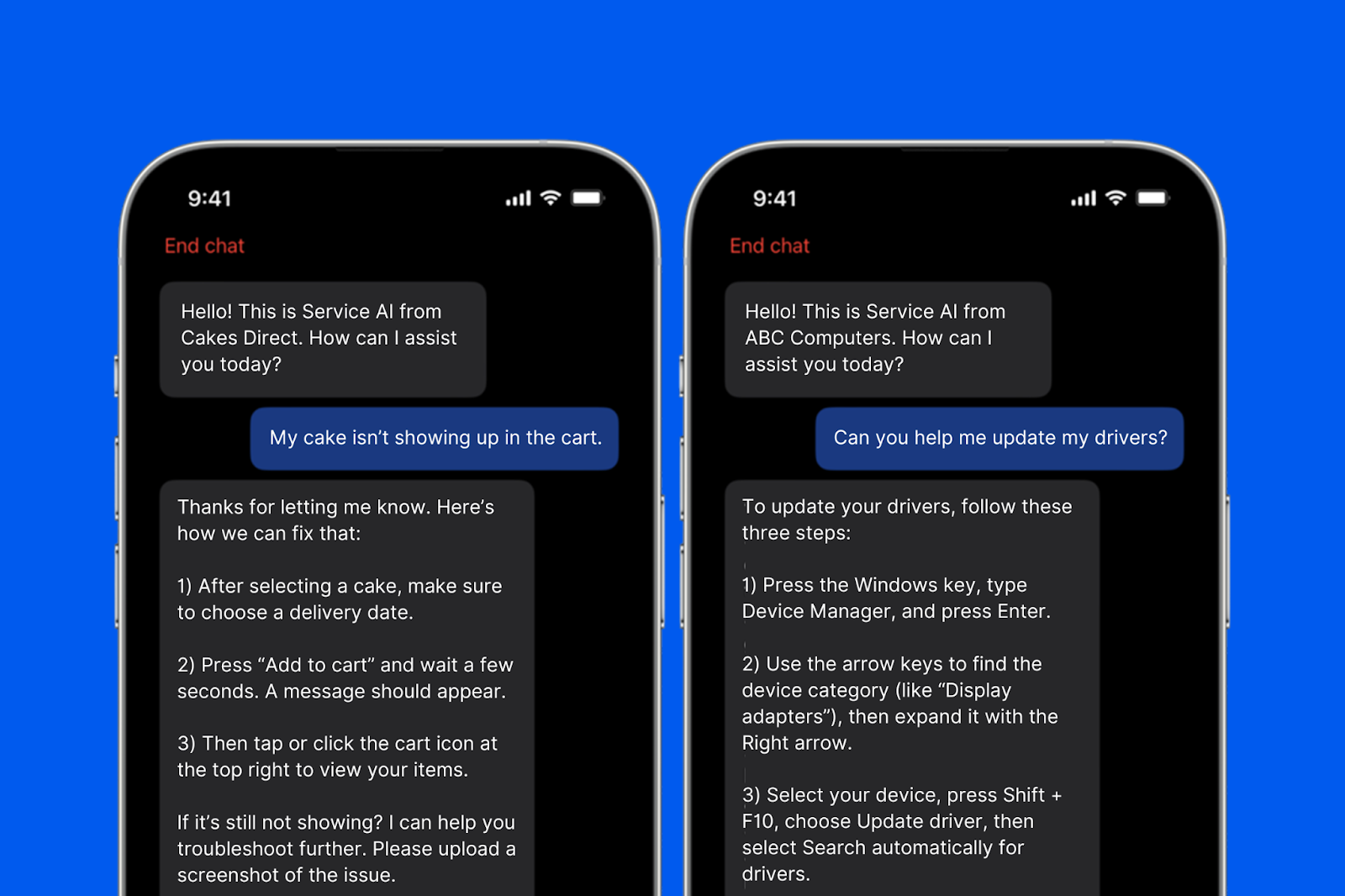
Multimodal systems let users communicate in whatever way is most natural for the moment and switch between modes without losing context. Someone can start a support conversation by typing, share an image of their problem, then switch to voice describing what happened within a single session. That flexibility reduces any friction causing users to abandon automated interactions and call in instead.
There is also a meaningful accessibility dimension here. Users with visual impairments, motor limitations, or reading difficulties benefit significantly from systems that do not require text as the primary input. Multimodal design is, in many respects, a more inclusive design.
Higher Accuracy Through Multi-Stream Inference
A system that only hears what you say misses everything communicated by how you say it. A system that only reads your words misses everything communicated by what you show it. Processing multiple streams simultaneously gives the system more information to work with, which generally produces better understanding of what a user actually needs.
The clearest example is sentiment analysis and emotion detection. Voice tone carries signals about frustration, urgency, or confusion that text alone cannot portray well. Facial expression data in video interactions adds in that missing context. A system that detects customer frustration early can escalate proactively rather than waiting for the conversation to deteriorate. That single capability has direct implications for customer satisfaction and first contact resolution rates.
Faster Resolution and Shorter Handle Times
When a customer can show a problem rather than describe it, the back-and-forth required to reach a resolution shrinks considerably. A visual input often communicates in one step what would otherwise take several exchanges to establish. For support teams measured on handle time and first contact resolution, that compression has a direct impact on operational performance.
Broader Self-Service Capability
Text-only self-service hits a ceiling quickly. Many requests are too complex, too visual, or too context-dependent to resolve through a chatbot that can only read typed input. Multimodal systems extend the range of what self-service can realistically handle, which means a higher share of interactions can be resolved without a human agent. That expanded deflection range is one of the stronger financial arguments for investing in multimodal infrastructure over a standard conversational AI deployment.
Enhanced Contextual Awareness
Context is what separates a useful response from a technically correct but practically unhelpful one. Multimodal systems work off richer context because they are working with more information at the top of the interaction.
Picture a customer uploading a photo of a product they own, asking a question about it in voice, then referencing a previous order. They're communicating in three channels at once. A multimodal system can hold all of that context simultaneously and use it to personalize the response in ways a single-channel system simply cannot. That depth of context is what enables more accurate handoffs when a human agent steps in. The agent gets a full picture of the interaction rather than a partial text log.
Industry Applications and Use Cases
There are many places where multimodal conversational AI can be applied and used to enhance both your agents' and customers' interactivity and communications. Here are a few places this technology shines:
Customer Service and Support
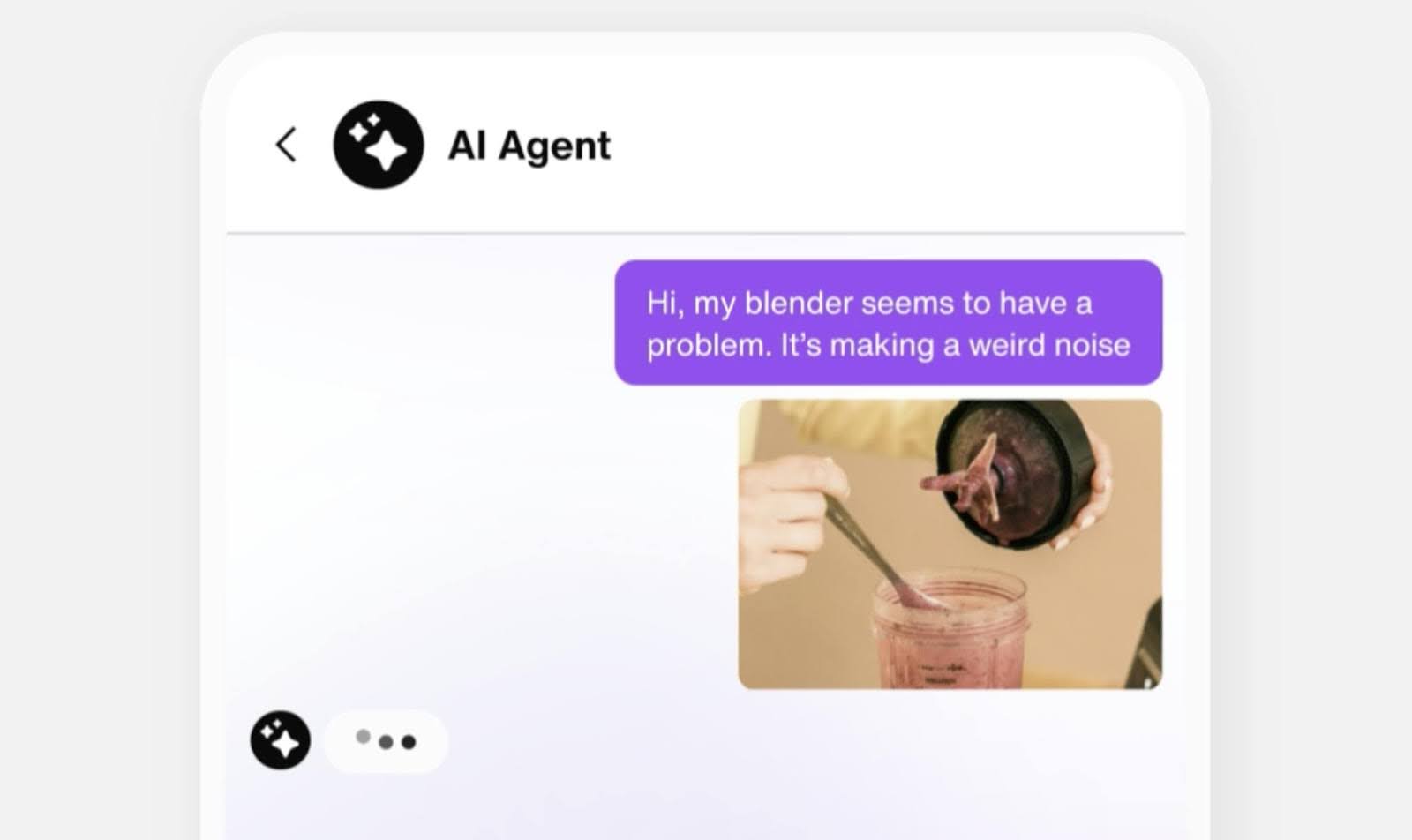
Visual troubleshooting is a strong immediate application. Instead of a customer describing a problem while an agent tries to interpret the description, the customer shows the problem via image upload or video. This saves time and sorts out what’s wrong faster. Image-based product queries work well in retail contexts, where a customer can photograph an item to communicate issues more precisely than any text description could.
Voice sentiment routing adds even more layers. When a system detects elevated stress in a caller's voice, it can adjust its approach or offer faster escalation to a human agent in real time, based on acoustic signals rather than keyword detection.
Healthcare and Accessibility
Visual symptom capture allows patients to photograph a visible condition as part of a triage conversation, giving the system and any reviewing clinician more accurate information than a written description provides.
Voice interfaces remove barriers for patients who cannot easily interact with text-based systems, whether due to age, disability, or physical circumstances. Hands-free voice navigation through appointment scheduling or pre-visit screening is a practical improvement over text-only intake flows for a significant share of patients.
Retail and E-Commerce
Beyond image-based product search, multimodal AI enables more natural shopping conversations. Customers can upload a screenshot of something they saw online and ask where to find something similar.
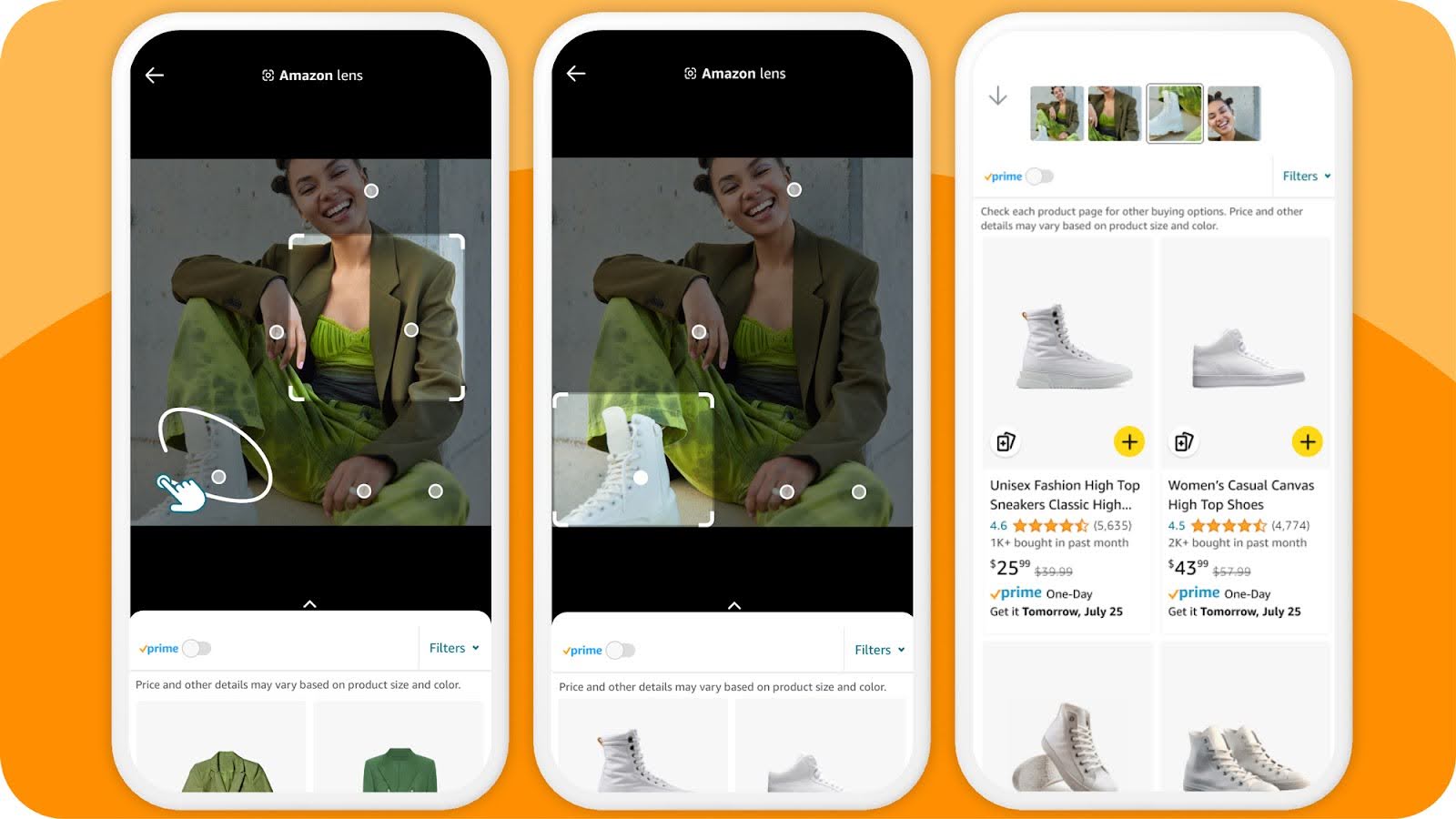
Likewise, they can describe what they are looking for using their voice while the system simultaneously processes reference images they uploaded. That combination produces more relevant results than either input alone would generate. Post-purchase, video-based returns processing, where a customer can show the condition of an item rather than describing, reduces disputes and speeds up resolution.
Financial Services
Multimodal AI adds meaningful capability in document-heavy financial workflows. A customer can photograph a statement, a check, or a form and ask questions about it directly within a conversation rather than navigating a separate document upload process. Voice biometric authentication adds a layer of security to account access that is more user-friendly than security question flows.

For fraud detection, combining voice tone analysis with transaction query patterns gives systems more signal to work with when flagging interactions that warrant closer review.
Field Service and Manufacturing
This is an underrated application. Technicians out in the field can use voice to interact with a support system hands-free while simultaneously sharing a video feed of the equipment they are working on. The system then will identify the component, pull the relevant documentation, and guide the technician through a repair process. This happens without requiring them to stop what they are doing to type. That combination of voice and vision in a hands-free context cannot be replicated via a text-based system, reducing both resolution time and the need to escalate to senior technicians for routine issues.
How to Evaluate Multimodal Conversational AI Platforms
Choosing a multimodal conversational AI platform hinges on a few important principles regarding which modalities you need, the metrics and benchmarks you plan to use, and scalability. Below we discuss briefly these factors:
Supported Modalities and Integration Depth
The most important question to ask any vendor beyond the basic ask of which modalities their platform supports is how deeply each one is integrated. Ask for a demonstration using a complex input that combines at least two modalities simultaneously. How the system handles that interaction illustrates how the platform will serve you better than a rote feature list.
Performance Metrics and Benchmarks
Cross-modal accuracy and response latency are two metrics that impact the hardest. Benchmark datasets like AudioVisual Scene-Aware Dialog (AVSD) and Visual Dialog exist to evaluate multimodal capability in a standardized way. Vendors whose systems have been evaluated against these benchmarks can substantiate accuracy claims than those relying on internal testing alone. Always ask for latency benchmarks under realistic load conditions.
Enterprise Readiness and Scalability
Multimodal systems tend to collect more sensitive data than text-only systems. Voice, video, and image inputs often carry biometric or personally identifiable information. You will need to confirm the platform meets the regulatory requirements (such as HIPAA or GDPR) relevant to your industry before deployment. Beyond compliance, evaluate API flexibility, deployment options including cloud and on-premise, and how the platform handles volume spikes under load.

